
Machine Learning is a fantastic emerging field of science which is gradually taking over every day life. From targeted advertisements to detection of cancerous cells, machine learning is everywhere. tasks that are performed at a high level using simple code blocks pose issue of “How is machine learning done? “.
In this video tutorial entitled The Complete Guide to Understanding Machine Learning Steps you’ll go through various steps required in building a machine learning model.
Table of Contents
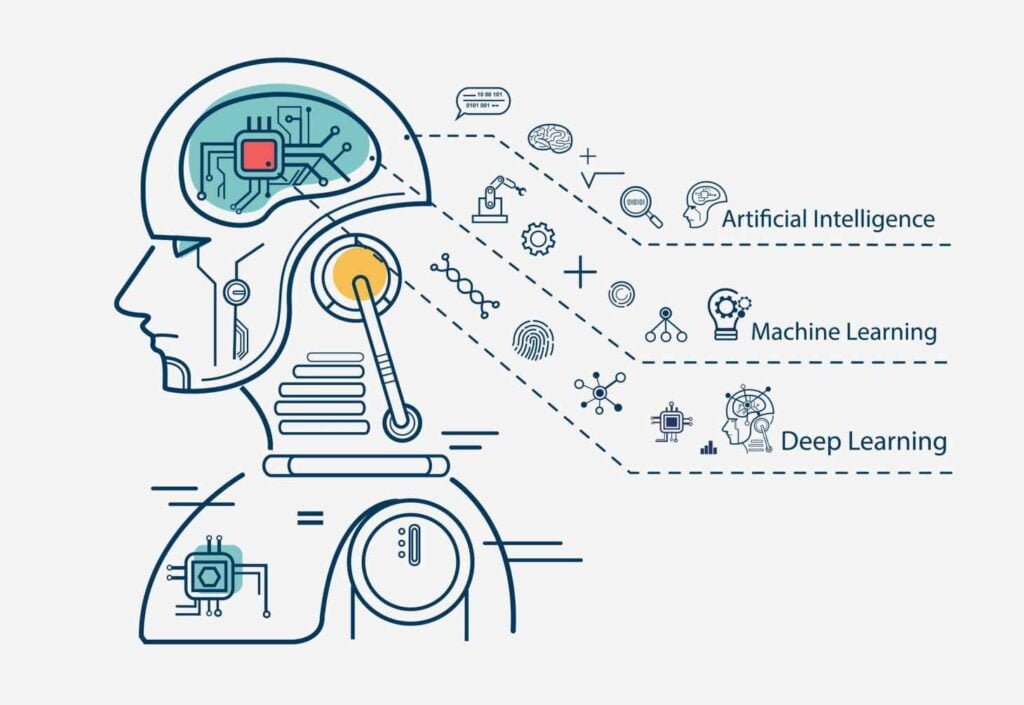
What Is Machine Learning?
Machine learning refers to process to create systems that can develop & learn on their own, through being programmed specifically.
The purpose for machine learning is to design algorithms which automatically assist system collect information & utilize that information to gain knowledge. Machines are required to look for patterns within information they collect & then use algorithms to take crucial decisions on their own.
The general idea behind machine learning is getting systems to behave & think like humans, exhibit human like capabilities as well as ability to think like humans. In real life it is possible to find machine learning models that can perform jobs like
- It is way of distinguishing legitimate emails from spam such as in Gmail
- Correction of spelling & grammar mistakes Autocorrect is way of correcting spelling & grammar mistakes.
Because of machine learning, world has seen systems for design that can display uncanny human like thinking. Machine learning can perform things like:
- Image & object recognition
- Detection of fake false news
- Understanding written or spoken words
- Bots on sites that communicate with humans. They are just like human beings.
- Self driven vehicles
Machine Learning Steps
The job of transferring machines with intelligence seems overwhelming as well as impossible. It is, however, actually straightforward. It is possible to break it down into seven major stages :
1. Collecting Data:
Like you, machines start learning from facts which you supply to them. It is of utmost important to gather reliable data to ensure..
that your machine learning model can find appropriate patterns. accuracy of information that you provide to machines determines precision of your machine learning model. If you are using incorrect or obsolete data, it will result in incorrect predictions of outcomes that don’t make sense.
It is important to get information from an authentic source since it could directly influence the result of the model. Good data is relevant, contains very few missing & repeated values,and has good representation of various subcategories/classes present.
2. Preparing Data:
When you’ve received your information it is time to format data.
- Gathering all information you’ve collected & then randomising results. This will ensure that data are evenly distributed & that order does not affect the process of learning.
- Clearing out data to get rid of undesirable data, invalid values row, columns & duplicate values Data type conversion & so on. It is possible to modify data structure by changing rows & columns or index of columns & rows.
- Explore information to see how its structured & comprehend relationships between different variables & classes in present.
- Separating clean data in two sets, an instructional set as well as a test set. the training set is what the model is taught from. a testing set can be used to verify precision of your model following training.
3. Choosing Model:
The ML model determines results.. what you get after performing machine learning algorithm on obtained data. It is crucial to select the right model that is applicable for specific tasks.
Through years, researchers & engineers came up with a range of models that are suitable for various applications like speech recognition, imaging recognition, predictive & more. In addition there is a need to check.. if your model can be used for categorical or numerical information & select accordingly.
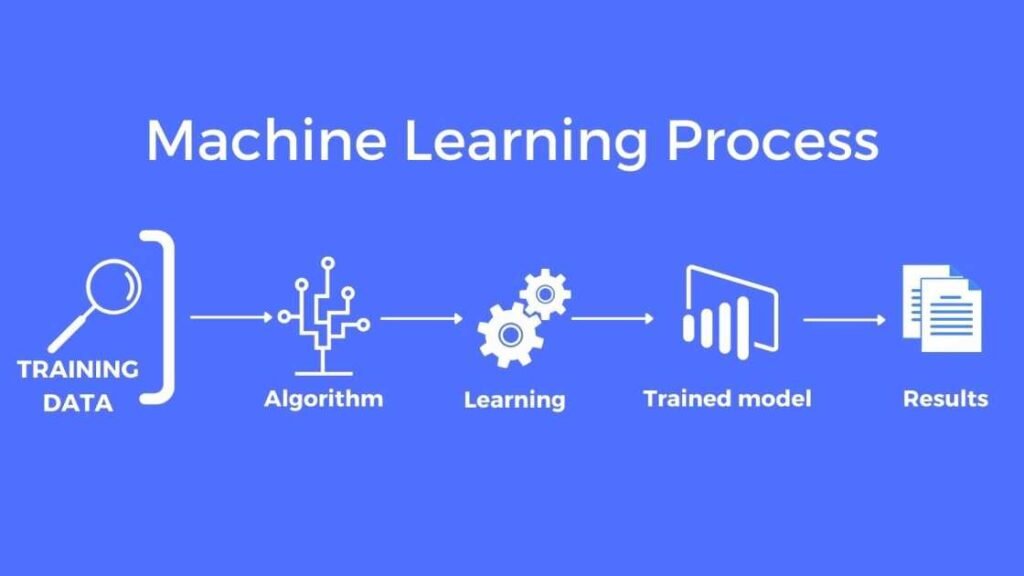
4. Training Model:
The training process is the main phase of machine learning. Training involves passing your data prepared into a machine learning model to find patterns & to make predictions.
This results in the model becoming more adept at learning from data so that it is able to complete tasks set. As time passes,and with help of training it gets more accurate in predicting.
5. Evaluating Model:
When youve completed training of your model you must check it for how well its doing. It is accomplished by evaluating efficiency of your model with previously unknown data. data that is not seen before is test set we divided our data into prior to the test. If tests were conducted using identical data being used to train & testing, you won’t be able to get precise measurement.
Because the model has already been working with data & detects similar patterns in the same way as it has previously. This gives you incredibly high accuracy.
In case of testing results, you will get a precise measure of how the model is going to be able to perform as well as its speed.
6. Parameter Tuning:
After youve created & assessed your model check.. if the accuracy of your model can enhance its accuracy in some manner. It is accomplished by adjusting parameters of the model. Parameters refer to variables of model which programmers usually determine. When you have a specific value for your parameter, accuracy is highest. term parameter tuning is used to determine right parameters.
7. Making Predictions
At the end of day you could make use of your model with no information to predict accurately.
Also read: Front end Development : Master Guide to Front-End Development 2024
Quantitative vs Qualitative/Categorical Data
Quantitative data refers to collection of data, like size & weight of any person who is part of an organization, as well as dimensions of entire group. Quantitative information can also be classified into two categories that are continuous & discrete data.
The term “discrete” does not refer to measurement.. which fall on the spectrum of measurement, instead it can refer to numbers that are counted such as amount of items in consumers shopping cart or total of transactions made in financial accounts.
Continuous data, on contrary, relates to data that can be meaningfully reduced into smaller parts & then placed in frame, such as amount of income a person earns or an employee’s pay or amount of money spent on financial transactions.
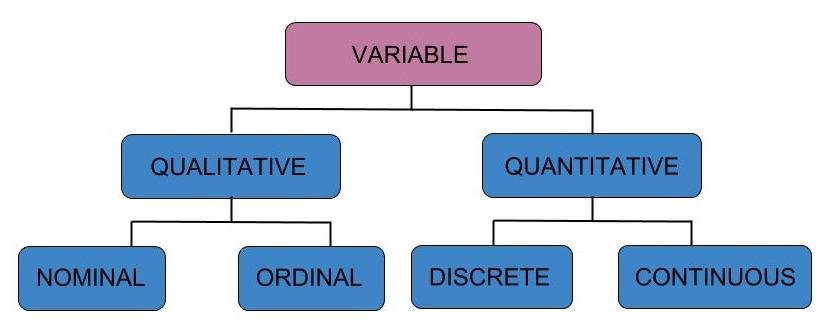
Qualitative data are non numeric for example, whether fraud is involved & whether reviews have negative or positive sentiments & whether purchase has high likely to be closed. Qualitative data tends to be categorical but also contains things such as text.
whether it’s tweets or tickets for customer service or documents. In the true sense of term categorical data is information that is related to categories. In contrast quantitative data refers to numbers.
Well explore the difference between qualitative & quantitative data. the latter focused on categorical information.
ML Applications: Classification
In the prior section, we looked at some examples of problems with regression that seek to forecast variables that are continuous. Another type of learned supervised issue is classifying, where we wish to place every sample to one or two or groups.
A bank, for instance, might want to know the likelihood. that a person who is loanee is able to repay loan in full or not. An email service provider may decide to create a system which blocks spam from your email inbox.
In each of these situations only options are two classes or categories, but you can also solve challenges with a variety of options. a lead scoring system may want to differentiate between neutral, hot, as well as cold leads. Computer vision challenges are usually multi-class challenges because we want to recognize multiple kinds of objects (cars or pedestrians, traffic signals & so on. ).
In this post well look at some algorithms employed to classify difficulties. But emphasis here is building an understanding of problem.. which is why we will not be discussing the mathematical basis of these algorithms in detail. Also we will focus only on issues that require binary classification (i.e. problems that have just two choices) to simplify the process.
What is amount of data I need to prepare an Model of ML?
Data is engine that creates energy that makes machine learning tick. Most of time more data you collect better your machine learning model will become. However, there are some situations where you could manage without much.
The models of Machine Learning are patterns matching machines. They only recognize & anticipate patterns previously observed. This is the biggest problem when it comes to machine learning. If you are trying to anticipate what might happen when you use fresh data, your model must have previously seen similar data previously.
It’s equally important to keep in mind that there’s no absolute standard for the amount of data youll need. In Akkios case, for instance, the leading scoring demo dataset includes nearly 40,000 rows & demo dataset for text classification contains just 1000 rows of data.
Both each achieve around 90 percent accuracy. A sample dataset for credit card fraud contains more than 300,000 rows of information! Explore the process of modelling your data & determine how you can achieve accurate results.